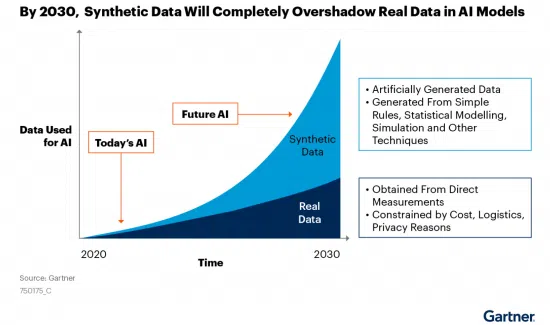
We have been examining the issues of obtaining data (enough of it! and high quality) and preparing that data to be used in training and validating models. One emerging way to deal with the issue of creating datasets for algorithm training is by creating synthetic data. This builds on the idea of using some of the novel AI methodologies such as generative adversarial networks to create new data for training of a new algorithm.
Health IT News recently wrote about Michigan Medicine having used such an approach in a recent project to develop a decision support tool that would improve pathologists’ ability to accurately diagnose brain tumors in the operating room, allowing them to both diagnose more quickly and more accurately. In this process, they were trying to develop a computer vision model that could identify regions that are likely to be diagnostic and provide a tentative diagnosis for the pathologist to consider when making their final interpretation
However, they were limited to using data that they had collected just from their own medical center. They took slides that had been warehoused and digitized them as a training data set to train the network. All in all, that resulted in about 300 patients with five different brain tumor diagnoses represented. They then aimed to validate the algorithm using a multi-institutional data set to ensure good performance across multiple medical centers. However, they noted an unexpected drop in accuracy when testing their model on images from other medical centers. For example, after they tested their model on new data from another medical center from Ohio State, accuracy dropped to 50%,”
Synthetaic, an AI company that creates synthetic data for AI algorithm training, was able to provide Michigan Medicine with a technique that improved how well its algorithms performed on new, unseen images from its own and other medical centers. The company’s expertise lies in closing the statistical gaps in AI training by generating high-quality, high-fidelity training data.
By using Synthetaic’s synthetic data, which was generated from very large pathology data sets, their model was better able to learn what to look for in pathology images. Putting it simply, by studying more images, the algorithm was able to get ‘smarter’ and therefore improve its diagnostic accuracy. To get more technical, the algorithm was able to improve because synthetic data allowed the team to augment the amount of data available for algorithm training. In particular, the team needed more data for specific brain tumor types that are uncommon or that were getting disproportionately high diagnostic error rates. Synthetaic was able to generate synthetic images around these two use-cases to solve this issue.
The problem of too little data is a common and major challenge with training computer vision models for clinical decision support. Using the methods such as generating synthetic data, the diagnostic accuracy of such models can be drastically improved. Companies like Synthetaic use generative adversarial networks to augment the existing data in a constructive way to improve computer-aided diagnostic systems.
The new algorithm trained with the additional synthetic data was able to achieve 96% accuracy across the major brain tumor types. This was a massive jump in performance compared to 68% accuracy without the use of synthetic data. Moreover, they were able to correctly diagnose 90% of the most challenging brain tumor class, primary central nervous system lymphomas, compared to only 70% without they synthetic data. These results include correctly classifying five out of six lymphomas that were misclassified by board-certified neuropathologists at the time of surgery. These results demonstrate the synergistic effect decision support tools and computer-aided diagnostics can have on improving patient care.