On another front, AI algorithms are designed to learn patterns in data and match them to an output. There are many AI algorithms, and each has strengths and weaknesses. Deep learning is acknowledged as one of the most powerful today, yet it performs best on large data sets that are well labeled for the precise output desired. We talked earlier in this chapter about using ML methods to do labeling. Sometimes, labeling is done not by hand, but by using an algorithm trained for a different, but similar, task. This approach, termed transfer learning, is very powerful. However, it can introduce bias that is not always appreciated.
Other algorithms involve steps called auto-encoders, which process large data into reduced sets of features that are easier to learn. This process of feature extraction, for which many techniques exist, can introduce bias by discarding information that could make the AI smarter during wider use – but that are lost even if the original data was not biased.
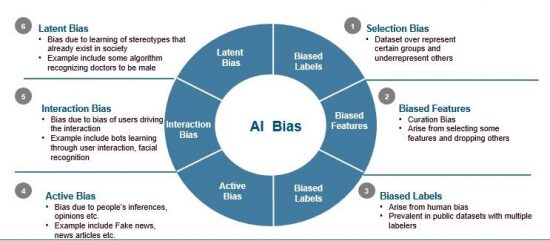
Bias in medical AI can lead to major issue, because making a wrong diagnosis or suggesting [the] wrong therapy could be catastrophic. Each of the types of bias we have discussed can apply to medicine. Bias in data collection is a critical problem. Typically, we only have access to data from patients we see or one or several medical institutions. These institutions, even taken together, may not represent the heterogeneity of the broader population
However, what about patients without insurance, or those who only choose to seek medical attention when very sick? How will AI work when they ultimately do present to the emergency room? The AI may have been trained on people who were less sick, younger or of different demographics. Or, increasing number of people who are using wearables, which can tell your pulse by measuring light reflectance from your skin [photoplethysmography]. Some of these algorithms are less accurate in people of color.
Vendor AiCure is used by pharmaceutical companies to assess how patients take their medications during a clinical trial. Using AI and computer vision via a patient’s smartphone, the vendor helps ensure patients get the support they need and that any incorrect or missed doses don’t interfere with a trial’s data.

In the company’s beginnings around 2011, staff started to notice their facial recognition algorithm was not working properly with darker-skinned patients – because the open-source data set they were using to train their algorithm was largely built using fair-skinned people.
They rebuilt their algorithm by recruiting Black volunteers to contribute videos. Now, with more than one million dosing interactions recorded, AiCure’s algorithms work with patients of all skin tones, which allows for unbiased visual and audio data capture.