In our last discussion, we tackled the issue of data as the bloodline for developing AI algorithms for various applications in healthcare. We also discussed how difficult it is to get that data and make sure that the dataset that you will use is high quality, diverse, and representative of the target patient populations. There is no issue that is more vital to the output of an AI algorithm than the data used to train and validate it.
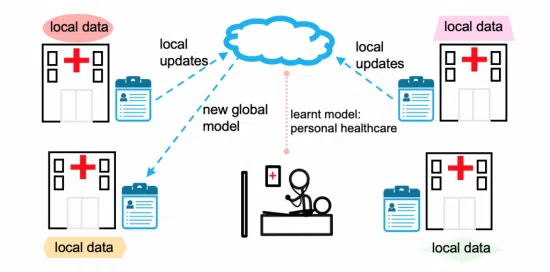
One possible solution is Federated AI. Federated AI, or federated learning, guarantees that the user’s data stays on the device.
For example, the applications that run specific programs on the edge of the network can still learn how to process the data and build better, more efficient models by sharing a mathematical representation of key clinical features, not the data.
Traditional machine learning requires centralizing data to train and build a model. However, with edge AI and federated learning combined with other privacy-preserving techniques and zero trust infrastructure, it’s possible to build models in a distributed data setup while lowering the risk of any single point of attack.
The application of federated learning also applies in cloud settings where the data doesn’t have to leave the systems on which it exists but can allow for learning. We call this federated cloud learning, which organizations can use to collaborate, keeping the data private.
Data fluency is a framework and set of tools to rapidly unlock the value of clinical data by having every key stakeholder participate simultaneously in a collaborative environment. A machine learning environment with a data fluency framework engages clinicians, actuaries, data engineers, data scientists, managers, infrastructure engineers and all other business stakeholders to explore the data, ask questions, quickly build analytics and even model the data. This novel approach to enterprise data analytics is purpose-built for healthcare to improve workflows, collaboration and rapid prototyping of ideas before spending time and money on building models.
Traditional healthcare systems are very siloed, and many organizations struggle to discover the value within their data and unlock actionable trends and clinical insights. Not only are data creation systems and teams isolated from data transformation systems and teams, but engineers and data scientists use coding languages while clinicians and finance teams use Word or Excel. The disconnect creates a situation where the data knowledge is translated outside of the programming environment. The transformations between system boundaries are lossy and without feedback loops to improve an algorithm or the code. Yet, all stakeholders need early and iterative access to the data to build health algorithms effectively and with greater transparency.