The data issue is so salient that many of the experts I spoke with mentioned that it will keep some of the key applications of AI in Healthcare at bay for now. Examples of this include clinical decision support. Decision support will be one of the last applications to gain widespread adoption due to the fragmented and unstructured nature of the data that needs to be used to develop and launch such applications. The challenge is even greater when you go live with such an algorithm and the data needs to feed into the algorithm real-time . Not to mention structured or un-structured data that remains fragmented and may not be easily available for the algorithm to provide the right output. These are not trivial issues for algorithm development or deployment in the real-world.
-
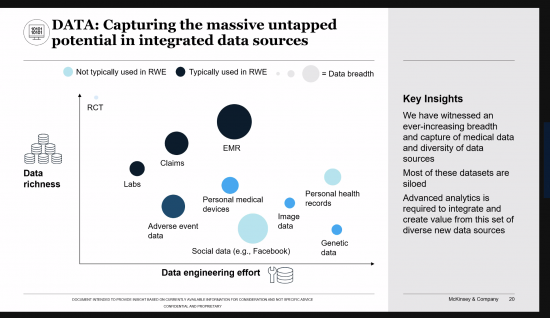
First is the difficulty of obtaining data sets that are sufficiently large and comprehensive to be used for training;. For many business use cases, creating or obtaining such massive data sets can be difficult. The right dataset has large quantity as well as diversity to fully be representative of the different types of patients that the algorithm will be used for. This data will need to come from the medical providers who performed these studies and will need to be de-identified and be representative of the target population. To pull together a good dataset and operationalizing the resulting algorithm in the real world, you have to deal with issues such as data standardization and interoperability. Emerging approaches such as Federated AI are introducing new possibilities to train algorithms without necessarily having to collect and centralize the data from the various institutions.
-
A key follow-up to the first issues is the risk of bias in data and algorithms. This issue touches on concerns that are more social in nature and which could require broader steps to resolve, such as understanding how the processes used to collect training data can influence the behavior of models they are used to train. For example, unintended biases can be introduced when training data is not representative of the larger population to which an AI model is applied. Thus, facial recognition models trained on a population of faces corresponding to the demographics of AI developers could struggle when applied to populations with more diverse characteristics. A recent report on the malicious use of AI highlights a range of security threats, from sophisticated automation of hacking to hyper-personalized political disinformation campaigns (1). Even with large datasets, they will have to guard against “overfitting,” where a model too tightly matches the “noisy” or random features of the training set, resulting in a corresponding lack of accuracy in future performance, and against “under-fitting,” where the model fails to capture all of the relevant features. Linking data across customer segments and channels, rather than allowing the data to languish in silos, is especially important to create value
-
Another big issue is the challenge of labeling training data, which often must be done manually and is necessary for supervised learning. Most of the early applications in healthcare in Radiology and Pathology are trained through “supervised learning”, which requires humans to label and categorize the underlying data. This is time and labor intensive. However promising new techniques are emerging to overcome these data bottlenecks, such as reinforcement learning, generative adversarial networks, transfer learning, and “one-shot learning,” which allows a trained AI model to learn about a subject based on a small number of real-world demonstrations or examples—and sometimes just one . (1)
-
Another major issue is the fragmented nature of the data in the real-world and how that would limit some key applications in the near-term such as decision support that would rely on complete patient data that comes from different sources. This is not nearly as critical of an issue if the scope of decision support is narrow: for example, in algorithms that help with the reading of radiological studies. In this instance, the data is limited to the radiology file and it is all structured. As such, one reasonable conclusion would be that AI applications that only need limited data available in a single file will be much easier to launch in the real-world than those that rely on data from multiple sources.
-
A related issue would be the difficulty of explaining in human terms results from large and complex algorithms: why was a certain decision reached? Product certifications in healthcare and in the automotive and aerospace industries, for example, can be an obstacle; among other constraints, regulators often want rules and choice criteria to be clearly explainable. (1) This is related to the labeling issue in that the output of a model may be more easily explained by looking at the input data and how it was labeled.
-
Another key issue is the generalizability of learning: AI models continue to have difficulties in carrying their experiences from one set of circumstances to another. That means companies must commit resources to train new models even for use cases that are similar to previous ones. This is especially true since each medical center may have unique population of patients that might be different than the one used to train an algorithm and thus the algorithms output on their population could be far from ideal. Already this has been seen with some of the algorithms that were launched in institutions where they were not developed. Transfer learning—in which an AI model is trained to accomplish a certain task and then quickly applies that learning to a similar but distinct activity—is one promising response to this challenge.